Machine Learning - Random Forest
Análise de crédito é uma área extremamente importante para provedores de crédito, neste sentido o uso de Inteligência Artificial para ánalise de risco de quem toma o crédito é muito comum já que por ela é possível estimar bons e más pagadores.
A análise abaixo é feita através de um Dataset que replica informações de clientes de um banco disponibilizadas pelo Kaggle.
Disponível em: https://www.kaggle.com/datasets/praveengovi/credit-risk-classification-dataset
### Importando bibliotecas
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import mean_squared_error as MSE
from sklearn.metrics import accuracy_score as accuracy
from sklearn.metrics import confusion_matrix, classification_report, ConfusionMatrixDisplay
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
from sklearn.model_selection import GridSearchCV
from imblearn.over_sampling import SMOTE
import matplotlib.pyplot as plt
import seaborn as sns
from zipfile import ZipFile ## biblioteca para descompactar arquivo .zip
Os dados foram coletado da plataforma Kaggle e são disponibilizados via arquivo zipado, portanto devemos extrair os arquivos
path = 'archive.zip' ## nome do arquivo .zip
## Usando ZipFile para extrair
with ZipFile(path, mode="r") as f:
## Listando os nomes dos arquivos
file_names = f.namelist()
print(file_names)
## Extraindo arquivos
f.extractall()
Análise e manipulação de dados
### Importando dados
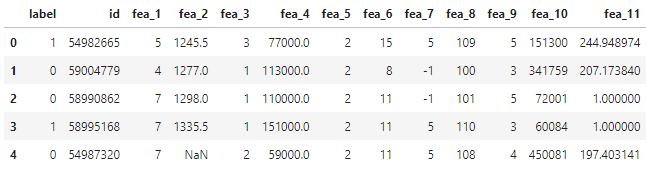
customer = pd.read_csv('customer_data.csv')
customer.head()
### Checando estrutura dos dados
customer.info()
### Checando dados da amostra
customer.info()
Com os código a cima é possível notar valores nulos no dataset, o que necessariamente deve ser tratado.
print(customer.isnull().sum()) ### Contagem de valores nulos
#### Substituindo valores nulos
for col in customer.columns:
if customer[col].isnull().sum() > 0:
customer[col].fillna(customer[col].mean(), inplace=True)
Processamento de dados
Em geral esses tipos de dados são desbalanceados, ou seja, terá bem mais observações de um respectivo dado dentro da amostra. Um exemplo de dados desbalanceados seria uma caixa de email, onde 99% dos emails que chagam são emails “limpos” (não nenhum tipo de má intensão) e apenas 1% dos emails são spam. Dessa maneira seria possível treinar um modelo de ML com esses dados que possuiria uma acurácia de 99%, neste caso ele poderia te recomendar todos os emails que chegam em sua caixa, juntamente com os emails maliciosos. Este é o problema de trabalhar com dados desbalanceados.
### Contando targets
sns.countplot(x='label', data=customer, palette='hls')
plt.show()
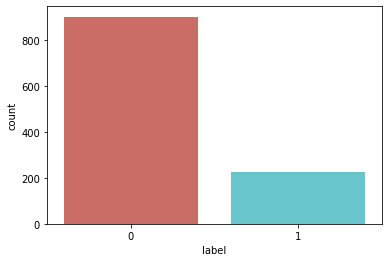
### Criando variaveis dos dados
X = customer.drop(['label'], axis=1)
y = customer['label']
Uma alternativa para se trabalhar com dados desbalanceados seria seria excluir os targets de maior frequência e deixa-los na mesma quantidade, porém isso prejudica o modelo já que irá diminuir a base de dados e com isso o desempenho irá diminuir i.e. acurácia. Para evitar esse problema é muito comum o uso do SMOTE (Synthetic Minority Oversampling Technique) que basicamente é um algoritmo replica a amostra de menor frequência sinteticamente, ou seja, não é simplismente um copia e cola ela terá distinção nas features.
### Aplicando SMOTE
sm = SMOTE(random_state=42)
X_res, y_res = sm.fit_resample(X, y)
Podemos fazer a contagem novamente
### Conatando dados
sns.countplot(y_res, palette='hls')
plt.show()

Preparando Pipeline
Finalizada a parte de tratamento de dados partimos para criação do pipeline
### Separando dados de treinameto
X_train, X_test, y_train, y_test = train_test_split(X_res, y_res, test_size=0.3, random_state=42)
O pipeline sera divididos em dois processos: i) Normalização dos dados para evitar distorções da amostra; ii) O algoritimo de Random Forest
Random forest é um algoritmo de Machine Learning muito utilizado, como um algoritimo de bagging tem essencialmente a ideia de diminuir a variância dos erros justamente fazendo uma interação na estrutura dos dados utilizando diferentes abordagens para isso.
### Montando pipeline
scaler = StandardScaler()
rf = RandomForestClassifier()
pipeline = Pipeline([('scaler', scaler), ('Random_Forest', rf)])
Para o modelo de Random Forest podemos testar diferentes hiperparametros para obtenção do que proporciona o melhor resultado, podemos entrão criar parametros para que o modelo teste.
### Parametros
criterion = ['gini', 'entropy']
n_estimators = [100, 200, 500]
max_features = ['auto', 'sqrt', 'log2']
random_state = [42]
### Criando um dicionário para os parametros
param_grid = dict(Random_Forest__criterion=criterion,
Random_Forest__n_estimators=n_estimators,
Random_Forest__max_features=max_features,
Random_Forest__random_state=random_state)
Utilizando a biblioteca GridSearchCV podemos testar esses parametros
### Aplicando GridSearchCV
clf_GS = GridSearchCV(pipeline, param_grid=param_grid, cv=5, scoring='accuracy')
clf_GS.fit(X_train, y_train)
Para verificar os melhores resultados podemos usar o comando do próprio GridSearchSV
### Imprimindo resultados
print('Melhor modelo: {}'.format(clf_GS.best_params_))
Testando o modelo
Podemos agora fazer a previsão para os dados de teste e gerar as métricas do modelo
### Fazendo predições
y_pred = clf_GS.predict(X_test)
### Testando a acuracia
acuracia = accuracy(y_test, y_pred)
rmse_test = MSE(y_test, y_pred)**0.5
print('Acuracia: ', acuracia)
print('RMSE: ', rmse_test)
Acuracia: 0.8666666666666667 RMSE: 0.3651483716701107
### Analisando a matriz de confusao
cm = confusion_matrix(y_test, y_pred)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=['Low risk', 'High risk'])
disp.plot(cmap='PuBu', colorbar=False)
### Report de classificacao
print(classification_report(y_test, y_pred))

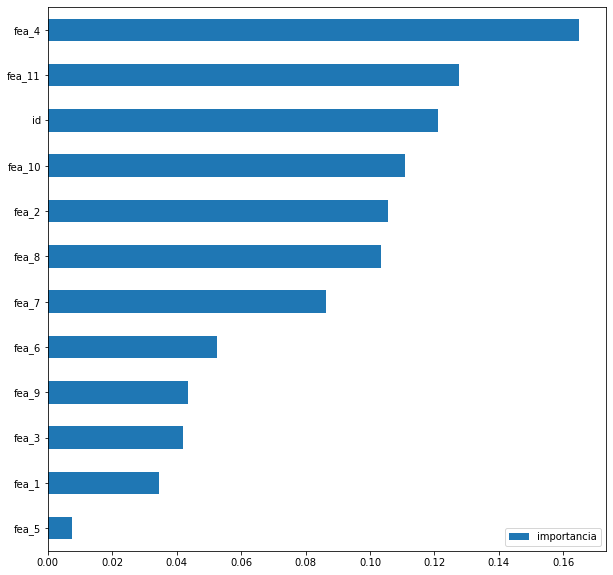
Também podemo análisar quais as features que possuiem maior relevância dentro do modelo de Random Forest
### Analisando fatores de importancia
importances = importances = clf_GS.best_estimator_.named_steps['Random_Forest'].feature_importances_
importances = pd.DataFrame(importances, index=X.columns, columns=['importancia'])
importances.sort_values(by='importancia', ascending=True, inplace=True)
importances.plot(kind='barh')