Trading Machine - Decision Tree
A idéia principal é testar indicadores técnicos para a explicação de retornos da ação PETR4, para isso foi usado o modelo de Random Forest e como inputs alguns indicadores técnicos tradicionáis, como:
- RSI
- Stochastic
- ROC
- Chaikin Money Flow
- Force Index
- KAMA
Além dos retornos passados e a % de quanto um fechamento ficou da máxima e mínima do dia desde 2010
Bibliotecas utilizadas:
import pandas as pd
import numpy as np
import ta ### biblioteca para analise de indicadores técnicos
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.metrics import classification_report
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
from sklearn.model_selection import GridSearchCV
import matplotlib.pyplot as plt
Base de dados:
A base de dados utilizada foi provida pela plataforma Economatica e comtém:
- Quantidade de negócios
- Volume
- Fechamento
- Abertura
- Mínima
- Máxima
- Médio
df = pd.read_excel('economatica.xlsx', parse_dates=True, index_col=0, skiprows=3)
df.rename(columns={'Volume$':'Volume'}, inplace=True)
Features:
A biblioteca ta foi utilizada para o cálculo dos indicadores:
df['Retornos'] = df.Fechamento.pct_change() ## retornos
df['Kama'] = ta.momentum.KAMAIndicator(close=df.Fechamento, window=21).kama() ## indicador Kama
df['ROC'] = ta.momentum.ROCIndicator(close=df.Fechamento, window=12).roc()
df['RSI'] = ta.momentum.RSIIndicator(close=df.Fechamento, window=14).rsi()
df['Stoch'] = ta.momentum.StochasticOscillator(close=df.Fechamento, high=df.Máximo, low=df.Mínimo,
window=14, smooth_window=3).stoch()
df['Chaikin_money'] = ta.volume.ChaikinMoneyFlowIndicator(high=df.Máximo, low=df.Mínimo, close=df.Fechamento,
volume=df.Volume, window=20).chaikin_money_flow()
df['Force_index'] = ta.volume.ForceIndexIndicator(close=df.Fechamento,
volume=df.Volume, window=13).force_index()
df['Normal'] = (df.Fechamento - df.Mínimo) / (df.Máximo - df.Mínimo)
Tratando dados
Houve a necessidade da limpeza de dados faltantes quando calculados os indicadores, como também a criação de targets para o modelo de classificação supervisionada
df = df.dropna() ## excluindo valores nulos
X = df[[
'Q Negs', 'Q Títs', 'Volume', 'Fechamento', 'Abertura', 'Mínimo',
'Máximo', 'Médio', 'Kama', 'ROC', 'RSI', 'Stoch', 'Chaikin_money',
'Force_index', 'Normal']] ## criando as features
y = np.where(df['Fechamento'].shift(-1) > df['Fechamento'], 1, -1) ## criando target
Através train_test_split foi criado a base de treinamento e teste
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=False)
Pipeline
Para uma melhor acurácia do modelo, houve a normalização dos dados, utilizando a bibliote StandardScaler e posteriormente o pipeline foi criado utilizando Pipeline. Foram inputs de paramentros para testar qual ajuste seria o melhor no modelo de classificação
scaler = StandardScaler()
dt = DecisionTreeClassifier()
pipeline = Pipeline(steps=[('Scaler',scaler),
('Decision_Tree', dt)])
criterion = ["gini", 'entropy']
max_depth = [2, 4, 6, 8, 10]
random_state = [3, 4]
### Criando parametros para comparação
parameters = dict(Decision_Tree__criterion=criterion,
Decision_Tree__max_depth=max_depth,
Decision_Tree__random_state=random_state)
Rodando modelo
clf_GS = GridSearchCV(pipeline, param_grid=parameters, scoring='accuracy', cv=5)
clf_GS.fit(X_train, y_train)
A acurácia do modelo comparado a base de treinamento e de teste foi ≅ 51 %
report = classification_report(y_test, clf_GS.predict(X_test))
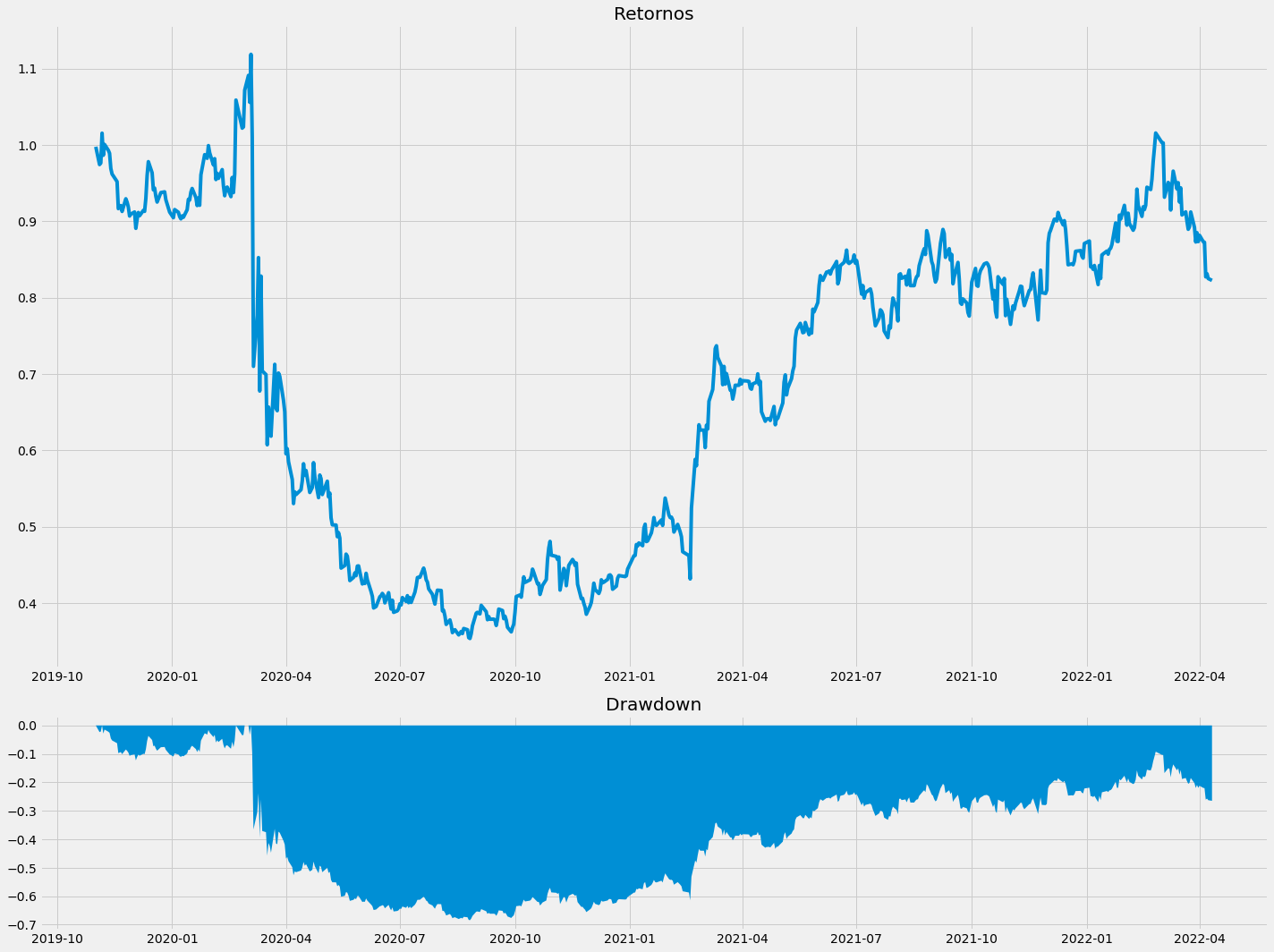
Analisando estratégia:
df['Strategy_returns'] = df['Retornos'].shift(-1) * clf_GS.predict(X) ### retorno da estratégia
### Calculando Drawdown
strategy = df['Strategy_returns'][X_train.shape[0]:]
wealth = 1000*(1+strategy).cumprod()
peaks = wealth.cummax()
drawdown = (wealth-peaks)/peaks
plt.style.use('fivethirtyeight')
f, (a0, a1) = plt.subplots(2, 1, figsize=(20, 15), gridspec_kw={'height_ratios': [3, 1]})
a0.plot((df['Strategy_returns'][X_train.shape[0]:]+1).cumprod())
a0.set_title('Retornos')
a1.plot(drawdown, linewidth=0)
a1.set_title('Drawdown')
a1.fill_between(drawdown.index, drawdown, alpha=1)
f.tight_layout()
Gráfico de retorno e drawdown: